앙상블 지도학습
지도 학습(supervised learning)은 학습 데이터에 예측의 목표가 되는 학습 레이블(label)이 포함된 학습 방법으로 기계학습(machine learning)에서 가장 기본적인 개념 중 하나이며 추천 시스템에서도 널리 사용된다. 다량의 데이터를 바탕으로 학습한 후 피처벡터만 주어졌을 때 학습 레이블에 해당하는 정보를 정확하게 예측하는 것이 목표가 된다. 지도학습이 추천시스템에 사용되는 과정을 살펴보자.
클릭 예측 모델과 데이터
좋은서점닷컴에 사용자가 방문하면 화면 상단에 10개의 서적을 보여준다고 생각해 보자. 그 중에 관심을 끄는 서적이 있다면 사용자는 해당 서적을 클릭하여 상세정보를 살펴보고 구매를 고려하게 될 것이다. 사용자의 관심사에 맞는 서적을 선정하기 위해, 해당 사용자가 각 서적을 클릭할 확률을 예측하는 모델을 만든다. 클릭할 확률을 정확하게 예측할 수 있다면 예측된 클릭 확률이 높은 순서로 추천 서적을 선정할 수 있기 때문이다.
클릭 예측모델의 학습데이터는 과거의 방문기록으로부터 얻을 수 있다. 방문기록은 어떤 사용자가 언제 방문하였는지, 그리고 사용자에게 보여준 서적의 목록과 그 중에 클릭한 서적들을 포함한다. 다음과 같은 간단한 방문기록을 생각해 보자.
| 시각 | 방문자 | 화면 상단에 보여준 서적 | 화면 상단에 보여준 서적 중 클릭한 서적 |
|---|---|---|---|
| 3개월 전 | 사용자1 | 서적 1, 3, 5, 6, 7, 12, 13, 14, 18, 20 | 서적 3 |
| 2개월 전 | 사용자2 | 서적 1, 2, 4, 8, 10, 11, 15, 16, 21, 28 | 서적 4, 15 |
| 1개월 전 | 사용자3 | 서적 3, 5, 9, 10, 12, 13, 20, 21, 22, 24 | 서적 21 |
사용자1과 사용자3은 한 개의 서적을 클릭하였고 사용자2는 두개의 서적을 클릭하였다. 물론 좋은서점닷컴을 방문한 후 화면 상단 10개의 서적 가운데 아무 서적도 클릭하지 않는 경우도 있을 테지만, 클릭이 없는 방문기록은 학습 데이터를 만들기 위한 데이터에서 제거하는 경우가 대부분이다.
학습 데이터를 구성하기 위해 피처벡터(feature vector)를 정의한다. 피처(feature)는 대상의 구체적인 정보를 숫자로 표시한 것이다. 여러 개의 피처를 모아서 벡터(vector)형태로 표현한 것을 피처벡터(feature vector)라고 부른다. 앞서 유사상품 추천에 대한 글에서 피처에 대해 살펴본 적이 있다. 유사상품 추천에서는 피처를 상품을 대상으로 정의했지만, 클릭모델에서는 (사용자, 상품)의 쌍을 대상으로 정의한다. 좋은서점닷컴의 클릭 예측 모델에서 생각할 수 있는 피처들을 예로 들면 다음과 같다.
| 피처의 정의 | |
|---|---|
| 피처1 | 해당 사용자가 가입한 후 경과한 개월 수 |
| 피처2 | 해당 사용자가 가입후 구매한 서적의 수 |
| 피처3 | 해당 사용자가 최근 1년간 구매한 서적의 수 |
| 피처4 | 해당 서적이 출판된 후 경과한 개월 수 |
| 피처5 | 해당 서적이 좋은서점닷컴에 판매된 총 부수 |
| 피처6 | 해당 서적이 최근 1년간 좋은서점닷컴에 판매된 총 부수 |
| 피처7 | 해당 사용자가 구매한 서적 가운데 해당 서적과 분류기호가 같은 서적의 비율 |
| 피처8 | 해당 사용자가 최근 1년간 구매한 서적 가운데 해당 서적과 분류기호가 같은 서적의 비율 |
| 피처9 | 해당 사용자가 해당 서적을 클릭한 횟수 |
피처벡터를 정의했다면 학습데이터를 구성할 수 있다. 클릭 모델에서 학습 레이블은 사용자가 해당 서적을 클릭했는지 여부이다. 이 학습 레이블은 클릭하지 않았음을 나타내는 0 또는 클릭했음을 나타내는 1의 값만을 가질 수 있는 이진(binary) 정보이다. 위의 방문기록을 바탕으로 학습데이터를 생성해 보면 다음과 같다.
| 피처벡터 | 학습 레이블 |
|---|---|
| (사용자1, 서적1)의 3개월 전 피처벡터 | 0 |
| (사용자1, 서적3)의 3개월 전 피처벡터 | 1 |
| (사용자1, 서적5)의 3개월 전 피처벡터 | 0 |
| (사용자1, 서적6)의 3개월 전 피처벡터 | 0 |
| (사용자1, 서적7)의 3개월 전 피처벡터 | 0 |
| (사용자1, 서적12)의 3개월 전 피처벡터 | 0 |
| (사용자1, 서적13)의 3개월 전 피처벡터 | 0 |
| (사용자1, 서적14)의 3개월 전 피처벡터 | 0 |
| (사용자1, 서적18)의 3개월 전 피처벡터 | 0 |
| (사용자1, 서적20)의 3개월 전 피처벡터 | 0 |
| (사용자2, 서적1)의 2개월 전 피처벡터 | 0 |
| (사용자2, 서적2)의 2개월 전 피처벡터 | 0 |
| (사용자2, 서적4)의 2개월 전 피처벡터 | 1 |
| (사용자2, 서적8)의 2개월 전 피처벡터 | 0 |
| (사용자2, 서적10)의 2개월 전 피처벡터 | 0 |
| (사용자2, 서적11)의 2개월 전 피처벡터 | 0 |
| (사용자2, 서적15)의 2개월 전 피처벡터 | 1 |
| (사용자2, 서적16)의 2개월 전 피처벡터 | 0 |
| (사용자2, 서적21)의 2개월 전 피처벡터 | 0 |
| (사용자2, 서적28)의 2개월 전 피처벡터 | 0 |
| (사용자3, 서적3)의 1개월 전 피처벡터 | 0 |
| (사용자3, 서적5)의 1개월 전 피처벡터 | 0 |
| (사용자3, 서적9)의 1개월 전 피처벡터 | 0 |
| (사용자3, 서적10)의 1개월 전 피처벡터 | 0 |
| (사용자3, 서적12)의 1개월 전 피처벡터 | 0 |
| (사용자3, 서적13)의 1개월 전 피처벡터 | 0 |
| (사용자3, 서적20)의 1개월 전 피처벡터 | 0 |
| (사용자3, 서적21)의 1개월 전 피처벡터 | 1 |
| (사용자3, 서적22)의 1개월 전 피처벡터 | 0 |
| (사용자3, 서적24)의 1개월 전 피처벡터 | 0 |
학습 데이터의 총 크기는 30개 이며, 그 중 4개의 학습 레이블은 1이고 나머지 26개의 학습 레이블은 0이다. 피처벡터의 차원(dimension)은 9이다. 실제 추천 시스템에서는 학습데이터는 이보다 훨씬 많을 것이고, 피처벡터의 차원도 더 큰 경우가 많다. 이 학습데이터를 이용해 이진 정보를 예측하는 이진 분류(binary classification)문제를 학습함으로써 클릭 예측 모델을 만든다.
의사결정나무 앙상블
추천 시스템에서 많이 쓰이는 이진 분류(binary classification) 방법은 의사결정나무 앙상블(decision tree ensemble) 방법이다. 의사결정나무 앙상블은 여러개의 의사결정나무(decision tree)를 모아서 만드는 모델을 말하는데, 이를 구성하는 의사결정나무는 피처벡터중 하나의 값을 비교하는 문장들과 그 결과에 따른 예측값으로 표현된 간단한 순서도같은 모델이다. 예를 들어보자.
�의사결정나무1:
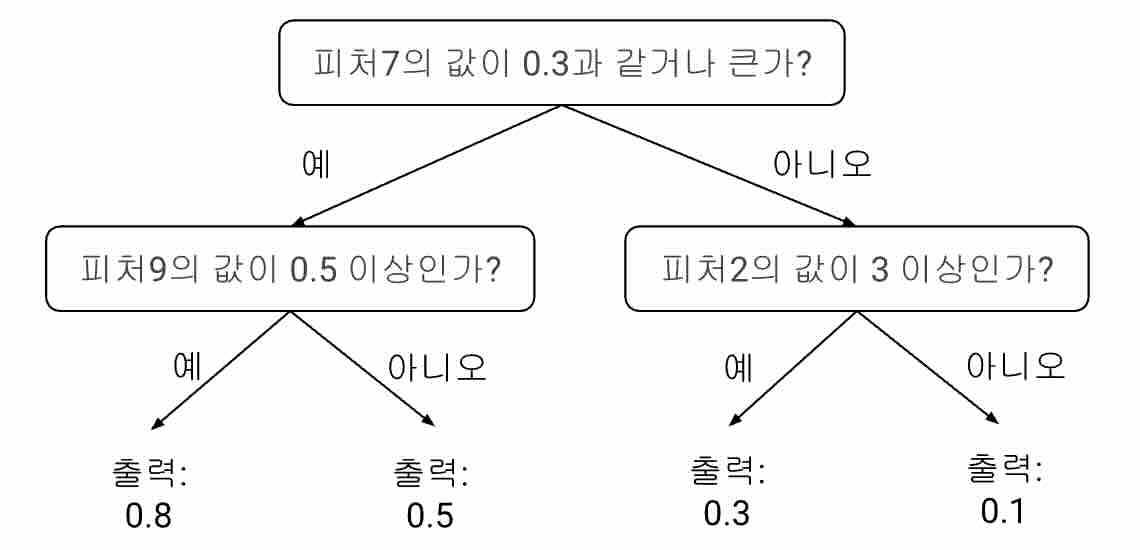
여기서 표현된 질문을 피처의 정의를 바탕으로 풀어서 쓰면 좀더 직관적으로 이해가 된다.
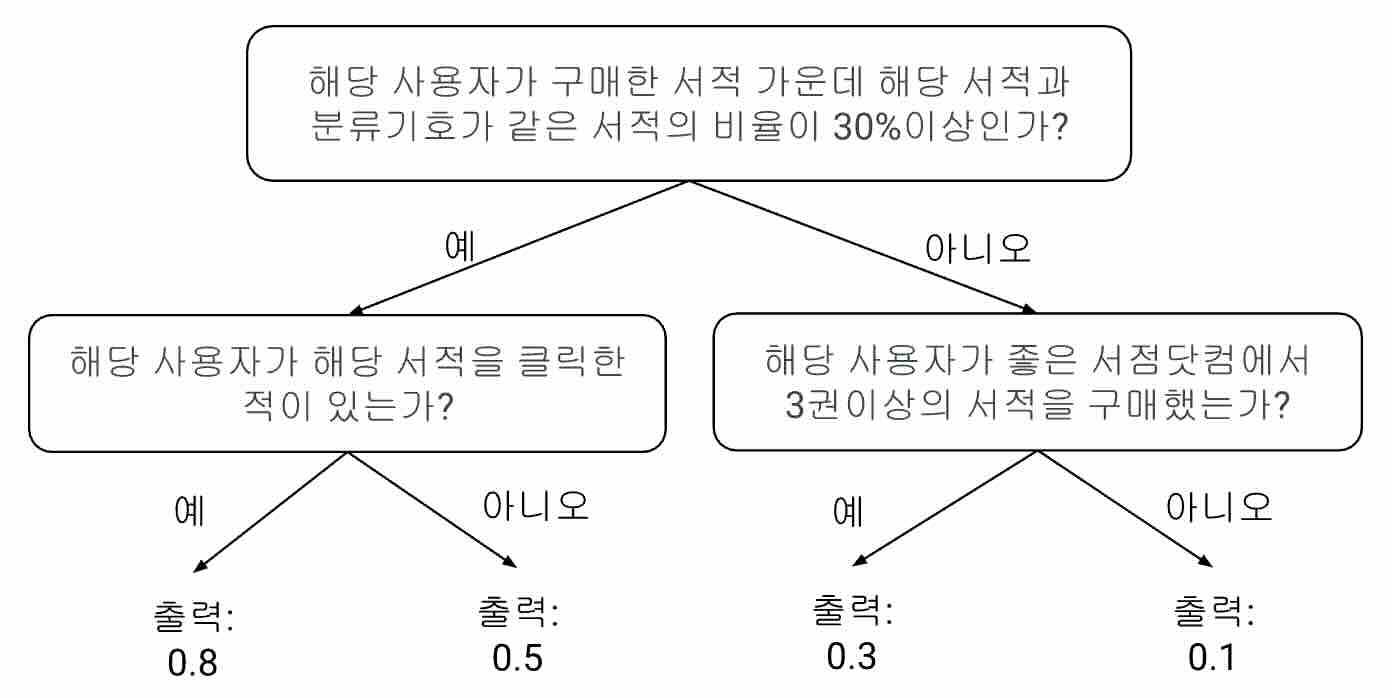
하나의 (사용자, 상품) 쌍에 대한 피처벡터를 이용하여 의사결정나무의 꼭대기부터 질문의 결과를 따라가면 바닥에 이르게 된다. 바닥에 있는 노드를 단말노드(leaf node)라고 하는데, 각 단말노드에는 해당 사용자가 해당 상품을 클릭할 확률을 나타내는 출력값이 정해져 있다. 예로 든 모델에서 한번의 출력을 계산하기 위해 고려하게 되는 질문의 개수가 2개인데 이를 의사결정나무의 깊이(depth)라고 한다. 출력의 가짓수는 4가지이며, 의사결정나무의 깊이가 깊을수록 출력의 가짓수가 늘어난다.
의사결정나무는 그 자체로서도 쓸모가 있지만, 많은 수의 의사결정나무를 함께 사용하는 경우 매우 강력하고 실용적인 방법이 된다. 이것이 의사결정나무 앙상블(decision tree ensemble) 방법이다. 앞서의 예로 든 의사결정나무1와 별도로 다음과 같은 의사결정나무2가 있다고 생각해 보자.
의사결정나무2:
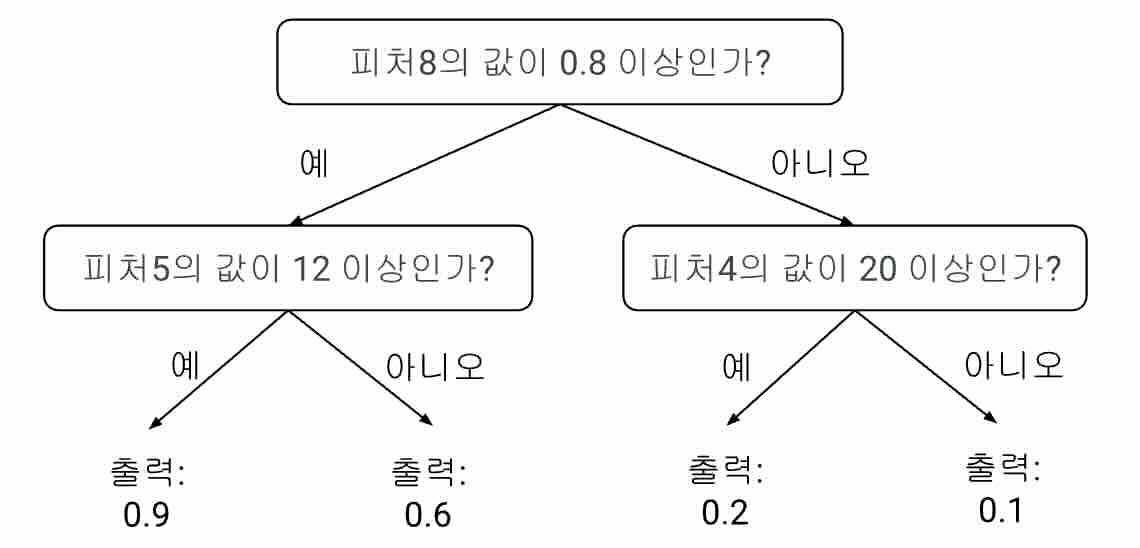
의사결정나무1의 결과와 의사결정나무2의 결과를 더하여 그 합을 출력하는 모델을 간단한 의사결정나무 앙상블 모델이라고 볼 수 있다. 예에서 단 두 개의 의사결정나무로 구성했지만, 실제로는 하나의 의사결정나무 앙상블에 수십또는 수백개의 의사결정나무를 사용하게 된다.
의사결정나무 앙상블의 학습
의사결정나무 학습의 핵심 개념은 학습 데이터를 둘로 나누는 과정을 반복하는 것이다. 어떻게 나누는지가 학습의 핵심이 되는데, 이진 분류(binary classification)에서는 기존 데이터를 두 묶음으로 나누어서 그 중 한쪽의 학습 레이블은 0의 비율이 높도록, 다른 한쪽은 1의 비율이 높도록 한다. 나눌 때에는 하나의 피처를 비교의 기준이 되는 기준점(threshold)과 비교한다. 어떤 피처를 이용하고 어떤 기준점을 이용하여 나누는지를 선택하는지가 학습의 중요한 과정인데, 그 과정을 대략적으로 보면 다음과 같다.
- 각각의 피처에 대해서
- 학습 데이터를 해당 피처의 최소값부터 최대값의 순서로 정렬한다.
- 정렬된 피처 값들을 차례로 기준점 후보로 고려하여 만약 학습데이터를 두 묶음으로 나눈다면 학습 레이블을 얼마나 깨끗하게 나누는지를 평가한다. 얼마나 깨끗하게 나누는지를 수치화하는 대표적인 방법으로 정보이론의 Information Gain이 있다.
- 고려한 기준점들 가운데 학습 레이블을 가장 깨끗하게 나누는 기준점과 그 기준점을 사용할 때의 Information Gain을 기록해 둔다.
- 모든 피처 중에서 학습 데이터를 두 묶음으로 나눈 결과가 가장 깨끗한 피처와 그 기준점을 고른다.
이 과정을 통해 학습 데이터를 두 묶음으로 나누고 나서, 똑같은 과정을 나누어진 각 묶음에 대해 다시 적용한다. 가령 전체 학습데이터를 두 묶음으로 나눈 후, 각 묶음에 대해서 한번 더 적용하면 총 네 묶음으로 나누게 되고, 이때 의사결정나무의 깊이(depth)는 2이다. 의사결정나무의 깊이(depth)를 미리 정해서 원하는 깊이가 되면 나누는 과정을 멈추거나, 그 전에 각 묶음에 담긴 학습 데이터의 숫자가 너무 작으면 더이상 나누지 않는 등의 추가적인 기준을 고려하기도 한다. 학습 데이터를 나누는 과정을 마치면, 가령 각각의 묶음에서 학습 레이블이 1인 비율을 계산하여 출력으로 결정할 수 있다. 예로 든 의사결정나무1과 의사결정나무2는 모두 깊이(depth)가 2이고 각 네 묶음의 결과에 대해 출력값이 정해져 있다.
의사결정나무 앙상블을 학습할 때에는 의사결정나무를 학습하는 것을 반복적으로 실행하게 되는데, 두 가지 대표적인 방법으로 경사 부스팅(Gradient Boosting Machine)과 랜덤 포레스트(Random Forest)가 있다. 이들 방법을 공부해보면 흥미로운 점이 많다. 자세한 내용은 기계학습(machine learning)분야의 다양한 자료들을 참고하자.
의사결정나무 앙상블의 장단점
분류문제(classification)를 위한 지도학습 방법에는 의사결정나무 앙상블이외에도 다양한 방법이 있으나, 그 중에 의사결정나무 앙상블이 널리 쓰이는 것은 몇가지 장점 덕분이다.
먼저 의사결정나무 앙상블은 학습 데이터가 많을 때 예측모델의 정확도를 높여주는 비선형(non-linear) 모델이다. 반대 개념인 선형(linear) 모델은 피처값들의 선형결합(linear combination)으로만 표현되는 모델을 말한다. 기계학습에서 선형 모델과 비선형 모델은 그 나름의 장단점이 있어서 적용되는 분야에 따라 모두 널리 쓰이지만, 인터넷 사이트의 추천 시스템에서는 주로 많은 양의 학습 데이터를 확보할 수 있어서, 비선형 모델이 주는 장점이 부각된다. 의사결정나무 앙상블에서 학습 데이터가 많아지면 나무의 갯수와 각 나무의 깊이등을 적절히 조절하여 예측모델의 정확도를 높일 수 있다.
의사결정나무에서 피처의 정규화(normalization)나 표준화(standardization)가 필요하지 않다. 정규화란 학습데이터 전체에서 해당 피처의 최소값이 0이 되고 최대값이 1이 되도록 변환하는 것을 말하고, 표준화란 학습데이터 전체에서 해당 피처의 평균은 0 표준편차는 1이 되도록 변환하는 것을 말한다. 로지스틱 회귀모델(logistic regression)이나 인공신경망의 경우 피처벡터를 정규화 또는 표준화하는 것이 예측 성능에 큰 영향을 미칠 수 있다. 반면, 의사결정나무에서는 정규화나 표준화를 거치치 않아도 예측 성능에 영향을 미치지 않아 시스템을 구성하기에 편리하다.
의사결정나무는 피처벡터에 누락된 값(missing value)이 있어도 별도의 처리없이 쓸 수 있다. 추천 시스템에서 피처에 누락된 값이 있는 경우는 매우 흔하다. 피처계산에 필요한 데이터를 접근할 수 없을 때 누락되기도 하고, 피처 계산에 나눗셈이 포함되어 있는데 분모에 0이 있는 등 계산이 불가한 경우도 있다. 위의 예에서 피처7을 보면 "해당 사용자가 구매한 서적 가운데 해당 서적과 분류기호가 같은 서적의 비율"인데 사용자가 구입한 서적이 없는 경우가 이에 해당한다. 누락된 피처를 다루는 방법 가운데 누락된 피처가 있는 학습 데이터들을 폐기하는 방법이 있는데, 이는 유용한 학습데이터를 버리게 될 뿐더러 학습 후 추론중에 누락된 피처가 있을 경우는 대응이 어렵다는 단점이 있다. 다른 방법으로 누락된 값들을 해당 피처의 평균(mean)이나 중간값(median)으로 대체하는 방법도 있다. 이 경우 피처가 정의된 맥락에 따라 평균이나 중간값으로 대체하는 것이 위험하지 않은지 주의할 필요가 있다. 의사결정나무 앙상블에서는 누락된 값을 그대로 사용하는 것이 가능하다. 학습 과정에서 해당 피처가 누락된 경우를 그대로 데이터 묶음으로 쓰는 것이 핵심이다. 위에서 설명한 의사결정나무의 학습에서 피처와 기준점으로 데이터를 두 묶음으로 나누었는데, 추가로 해당 피처가 누락된 학습 데이터들을 따로 떼어내어 세 번째 묶음으로 만드는 것이다. 이렇게 하면 해당 피처가 누락된 경우에 대해 별도의 예측치를 출력할 수 있다. 이 방법은 학습 데이터를 폐기하지 않고 모두 쓸 수 있으며, 평균이나 중간값으로 대체하는 등의 추가적인 처리를 하지 않아도 되어 편리하고, 학습데이터가 충분하다면 예측 성능도 높일 수 있다. 다만, 의사결정나무 앙상블을 학습시키는 소프트웨어가 모두 누락된 값의 별도 처리를 지원하는 것은 아니고, 널리 쓰이는 XGBoost의 경우 이 기능을 제공한다.
의사결정나무의 또다른 특징으로 범주형(categorical) 정보를 다룰 수 있다는 점이 있다. 기계학습 모델들은 일반적으로 숫자로된(numerical) 피처를 기반으로 작동하기에 범주형(categorical) 정보는 원-핫(one-hot) 인코딩 등의 방법을 이용해 피처벡터로 변환하는 것이 일반적이다. 그러나 의사결정나무에서는 이 과정을 거치지 않은 방법도 가능한데, 학습 데이터를 묶음들로 나누는 데에 범주형 정보를 직접 사용할 수 있기 때문이다. 예를 들어 좋은서점닷컴에서 범주형 정보인 분류기호에 문학, 역사, 자연과학, 사회과학의 네 가지가 허용된다고 해 보자. 원-핫(one-hot) 인코딩을 사용하면 차원(dimension)이 4인 피처벡터를 생성하게 된다. 의사결정나무는 한번에 하나의 피처를 사용하여 데이터를 나누므로, 원-핫(one-hot) 인코딩된 피처벡터를 사용하여 학습하는 경우 "분류기호가 문학인 경우", "분류기호가 문학이 아닌 경우"와 같이 하나의 분류기호 값을 사용하여 데이터 묶음을 나누는 학습을 하게 된다. 반면 범주형 정보를 그대로 사용하여 학습하는 경우 "분류기호가 문학이거나 역사인 경우", "분류기호가 자연과학이거나 사회과학인 경우"와 같이 나누는 방법도 가능해 진다.
의사결정나무 앙상블의 단점으로 학습 데이터가 적은 경우 예측의 정확도가 높지 못하다는 점이 있다. 또한, 앙상블에 쓰인 나무의 갯수가 많거나 나무의 깊이(depth)가 깊은 경우 학습과 추론에 시간이 오래 걸린다는 점도 단점이다. 다만, 사용자가 많은 인터넷 사이트의 추천시스템에서는 충분한 양의 학습데이터를 확보할 수 있고, 학습과 추론에 걸리는 시간은 병렬처리를 통해 최적화가 많이 되어 있다.
피처의 종류와 계산
좋은서점닷컴에 총 100개의 책이 있다고 할 때, 의사결정나무 앙상블을 이용하여 추천 상품을 선정하는 계산과정을 생각해 보면 다음과 같다.
- 사용자1이 좋은서점닷컴을 방문한다.
- (사용자1, 서적1), …, (사용자1, 서적100)에 대해 각각 피처1, …, 피처9를 계산한다. 계산의 결과는 차원이 9인 피처벡터 100개이다.
- 미리 학습된 의사결정나무 앙상블을 각 피처벡터에 적용하여 (사용자1, 서적1), …, (사용자1, 서적100) 의 클릭확률 예측치를 계산한다.
- 클릭확률이 높은 10개의 서적을 사용자1에게 보여준다.
한 명의 사용자에게 추천 상품을 선정하기 위해 판매 가능한 서적만큼 피처벡터가 필요하고, 따라서 피처벡터들을 준비하는 것이 계산의 중요한 부분을 차지한다. 피처1, ..., 피처9를 계산에 필요한 정보의 단위에 따라 다음과 같이 분류할 수 있다.
- 사용자 단위 피처: 피처의 값이 사용자가 누군지에 의해 결정되는 피처. 피처 1, 2, 3이 있다.
- 상품 단위 피처: 피처의 값이 어떤 상품인가에 의해 결정되는 피처. 피처 4, 5, 6이 있다.
- 사용자-상품단위 피처: 피처의 값이 사용자가 누군지와 어떤 상품인가 두가지에 의해 결정되는 피처. 피처 7, 8, 9가 있다.
이처럼 피처들을 분류하면 지도학습을 이용해 추천시스템을 효과적으로 구성하는데 도움이 된다. 예를 들어 사용자1을 위한 추천상품을 선정하기 위해 (사용자1, 서적1), ..., (사용자1, 서적100) 에 대한 피처벡터를 계산하는 과정을 생각해 보자. 상품 단위 피처와 사용자-상품단위 피처는 매 서적마다 계산결과가 다르지만, 사용자 단위 피처들인 피처1, 2, 3은 한번만 계산한 후 모든 서적에 반복 사용할 수 있다.
피처를 계산한 뒤 캐싱(caching)하거나 옮겨야 할 필요가 있을 때에도 마찬가지이다. 사용자 단위 피처는 사용자 ID를 이용하여 저장하고, 총 사용자 수 만큼의 공간을 필요로 한다. 상품 단위 피처는 상품 ID를 이용하여 저장하고, 총 상품 수 만큼의 공간을 필요로 한다. 사용자-상품단위 피처는 사용자 ID와 상품 ID의 조합을 이용하여 저장하고, 사용자의 상품의 조합의 수만큼이 필요하므로 훨씬 더 많은 저장공간을 필요로 한다.
피처 계산을 위한 시스템 구성에 크게 두 가지 접근법이 있다. 첫번째는 백엔드(backend)에서 계산하는 방법이다. 예를 들어 피처4: "해당 서적이 출판된 후 경과한 개월 수"를 계산한다면, 먼저 데이터베이스로부터 서적의 출판년도를 알아낸 후 현재시각과 비교하여 개월 수를 계산한다. 피처2: "해당 사용자가 가입후 구매한 서적의 수"의 경우라면 사용자 구매기록의 개수를 찾는 데이터베이스 질의문(query)을 실행하게 되고, 피처5: "해당 서적이 좋은서점닷컴에 판매된 총 부수"의 경우도 비슷한 질의문을 실행하게 된다.
매 피처마다 데이터베이스 질의문(query)을 실행하는 것은 데이터베이스에 지나치게 부담을 줄 뿐더러 응답시간(latency)이 너무 길어지는 문제가 있기에 효율성을 높이기 위한 방법들이 필요하다. 먼저 여러개의 피처에 공통으로 사용되는 정보가 있다면 한번에 질의하여 반복 사용한다. 가령 피처 2, 3, 7, 8의 경우를 생각할 수 있다. ”해당사용�자의 전체 구매목록”을 한번에 알아낸 후에 피처2의 경우 전체 목록을 그대로 사용하는 반면, 피처3의 경우 최근 1년에 구매한 경우만을 골라서 사용, 피처7의 경우 해당 서적과 분류기호가 같은 경우만을 골라서 사용하여 계산이 가능하다. 피처계산에 필요한 데이터베이스 질의문(query)들 가운데 실행시간이 긴 질의문들의 결과를 미리 실행하여 캐싱(caching)하는 것도 효과적이다. 예를 들어 "해당사용자의 전체 구매목록"을 캐싱하는 경우라면, 사용자 방문시에 질의문을 실행하는 대신 서적 구매가 일어날 때에만 실행하고 그 결과를 캐싱해 둠으로써 질의문을 실행하는 빈도도 줄이고 응답시간도 개선할 수 있다.
피처를 계산하는 두번째 방법은 데이터 웨어하우스에서 계산하는 것이다. 데이터 웨어하우스는 다량의 데이터를 처리하는데 강점이 있어서 간단한 형태는 물론 복잡한 형태의 질의문도 처리할 수 있다. 반면, 질의문 실행시간이 비교적 길기 때문에 사용자 방문시 실시간으로 실행하는 것은 어렵다. 일반적인 방법은 피처를 계산하는 질의문들을 주기적으로 데이터 웨어하우스에서 실행하여 그 결과를 백엔드(backend)로 옮겨 두는 것이다. 예를 들면 매일 한번 모든 피처를 계산하는 방법을 생각할 수 있다.
두 방법 사이에 장단점이 있다. 백엔드에서 계산하는 방법의 장점은 사용자나 상품의 가장 최신정보를 사용하여 피처를 계산할 수 있다는 것이다. 반면 피처계산에 필요한 정보를 얻기 위해 데이터베이스 질의문을 실행하다보면 응답시간이 길어지는 단점이 있어서, 질의문들의 결과를 미리 실행하여 캐싱(caching)하는 등의 노력을 통해 응답시간을 개선시켜야 한다. 데이터 웨��어하우스에서 계산하는 경우 모든 피처가 미리 계산되기 때문에 응답시간이 빠르다. 반면, 피처를 주기적으로 계산하여 백엔드로 옮기는 작업이 부담이고, 갱신주기 사이에는 새로운 정보가 피처에 반영되지 않는 단점이 있다. 두 방법의 장단점을 저울질할 때 총 사용자의 수, 총 상품의 수, 사용자의 사이트 방문 빈도 등을 고려하게 된다. 또한 두가지 방법을 동시에 사용하며 피처의 종류에 따라 알맞은 방법을 사용하는 것도 좋은 방법이다.
학습데이터를 위한 피처 로깅 또는 재계산
지도학습으로 추천시스템을 도입하고 나면 학습 모델의 성능을 단계적으로 개선시켜나가게 되는데, 많은 경우 새로운 피처를 추가함으로써 성능 개선을 꾀한다. 새로운 피처를 구현하고, 새로운 피처가 포함된 학습 데이터를 만들고, 이를 이용한 새로운 학습모델을 만드는 작업을 반복하게 되고, 이 반복작업을 쉽고 효과적으로 하는 것이 매우 중요하다. 여기서 새로운 피처를 구현한 후 학습 데이터를 만드는 일에 대해 생각할 점들을 이야기해 보자.
학습 데이터를 구성할 때에는 반드시 사용자가 방문한 시점에 계산되었거나 또는 그 이전에 미리 계산되어 저장해 둔 피처를 사용해야 한다. 이를 간과하여 학습 레이블이 발생한 이후 시점의 피처를 사용하면, 학습한 모델의 예측성능이 급격히 하락할 위험이 있다. 피처가 계산된 시점을 안전하면서도 효과적으로 다루어서 학습에 필요한 데이터를 만드는 일에 많은 노력을 기울이게 된다. 이때 꼭 필요한 기능이 (사용자 , 서적 )의 피처벡터를 과거 시점을 기준으로 구성하는 일이다.
과거 시점의 피처벡터를 구성하기 위해 사용되는 방법의 하나로 피처 로깅이 있다. 사용자가 방문한 시점에 사용한 피처를 로그형태로 기록하고, 카프카(Apache Kafka)나 그와 유사한 시스템을 이용해 처리하여 데이터 웨어하우스에 저장해 둔다. 학습 데이터를 구성할 때에는 데이터 웨어하우스에 저장된 피처기록에서 원하는 시점의 피처벡터를 찾기만 하면 그대로 사용할 수 있다. 피처 로깅은 간단하면서 안전하다.
피처 로깅의 단점은 새로운 피처를 추가할 때에 나타난다. 오늘 새로운 피처를 구현했다고 하면, 내일부터 발생하는 피처로그에는 새로운 피처가 포함되게 될 것이다. 하나의 모델을 위한 학습 데이터는 일정기간의 방문기록을 바탕으로 만들게 되는데, 위의 예에서는 3개월 전의 피처벡터가 학습 데이터에 포함되어 있다. 즉, 오늘 구현한 새로운 피처를 포함한 학습데이터가 준비되기 까지 3개월이 필요하다는 것을 뜻한다. �이처럼 새로운 피처를 구현하고 나서 일정시간동안 기다려야 학습 모델에 사용할 수 있다는 점이 피처 로깅의 단점이 된다.
이같은 단점을 피하면서 과거 시점의 피처벡터를 구성하기는 방법은 과거의 피처를 재계산하는 것이다. 재계산이 가능하기 위해서는 몇가지 조건이 필요한데, 하나는 피처를 구현하는 소스코드가 재계산이 가능하도록 구현되어야 한다는 점, 다른 하나는 재계산을 위해 과거 시점의 데이터를 재구성할 수 있어야 한다는 점이다. 예를 들어보자. 피처 4: "해당 서적이 출판된 후 경과한 개월 수"는 서적의 출판일과 현재시각의 차이를 본다. 재계산이 가능한 구현을 위해서는 항상 현재 시각을 사용하는 대신, 추론을 위한 계산에는 기준시각으로 현재시각을 사용하고, 과거 시점의 피처 계산을 위해서는 기준시각으로 과거 시점을 이용해야 한다. 피처 2: "해당 사용자가 가입후 구매한 서적의 수"의 경우에는 데이터의 재구성이 필요하다. 과거 시점의 피처를 재계산할 때에는 기준시각 이후에 발생한 구매기록은 제외해야 하기 때문이다.
피처 재계산 방식의 장점은 새로운 피처를 구현하고 나서 학습 데이터가 형성되는 기간동안 기다리지 않아도 된다는 점이다. 그에 따르는 부담도 따른다. 피처를 구현할 때 재계산이 가능하도록 강제하는 것이 우선이다. 그리고 재계산을 통해 학습데이터를 생성하는 작업은 계산량이 많을 수 있기 때문에 대용량 서버와 병렬화등을 이용하여 자동화를 시도한다. 피처계산에 필요한 정보가 불변한(immutable)것인지도 생각할 필요가 있다. 가령 피처 4: "해당 서적이 출판된 후 경과한 개월 수"를 정확하게 계산하기 위해 서적의 출판일이 필요한데, 신규서적의 경우 처음에는 출판일 정보가 누락되어 있다가 나중에 입력되는 등의 이유로 바뀌기도 한다. 이처럼 피처 계산에 필요한 정보가 중간에 바뀐다면, 학습을 위해 재계산된 피처가 해당 시점에 추론을 위해 사용된 피처와 달라 위험할 수 있다. 이를 피하기 위해 피처 계산을 위한 데이터의 과거 버전을 저장하기도 한다.
피처 로깅과 피처 재계산의 장단점을 저울질 할 때, 학습에 필요한 데이터를 모으기 위해 어느 정도의 기간이 필요한지를 고려한다. 위에서 사용한 좋은서점닷컴의 예에서는 3개월 전의 데이터도 사용했지만, 경우에 따라서는 1-2주 정도의 짧은 기간으로도 충분할 수 있고, 3개월보다 긴 기간이 필요할 수 도 있다. 짧은 기간으로도 충분하다면 부담이 적은 피처 로깅 방식의 장점이, 긴 기간이 필요하면 피처 재계산의 장점이 크게 느껴질 것이다.
행렬분해와 인공 신경망 모델을 피처로 이용하기
지도학습에서 다른 모델의 출력을 피처로 사용할 수 있다. 앞서 설명한 행렬 분해와 인공 신경망등의 모델을 학습한 후 그 출력을 지도학습에 이용하면 각각의 모델보다 예측 성능이 더욱 높아진 강력한 모델을 만들 수 있다. 의사결정나무 앙상블은 이처럼 여러개의 모델을 통합하는 능력이 뛰어나다.
앞선 예에서 사용한 피처1, …, 피처9에 추가로 다음과 같은 피처10, 피처11을 생각해 보자.
| 피처의 정의 | |
|---|---|
| ... | ... |
| 피처10 | 행렬분해에서 사용자 벡터와 상품 벡터의 내��적 |
| 피처11 | 두개의 탑 인공신경망의 사용자 탑과 상품 탑의 출력사이의 내적 |
이렇게 총 11개의 피처를 사용하여 학습 데이터를 구성할 수 있다. 피처1, …, 피처9는 설계자의 직관을 이용해 수동으로 설계한 피처들인 반면 피처10과 피처11은 학습을 통해 얻는 모델의 출력을 피처로 사용한 것이다.
의사결정나무에서 각 피처가 출력에 미치는 영향을 수치화 한 것을 피처 중요도(feature importance)라고 하는데, 모델 기반의 피처들을 수동으로 설계한 피처들에 비해서 피처의 중요도가 높다. 행렬분해나 인공신경망 모델들은 그 자체로도 예측능력이 높기 때문이다.
모델 기반 피처를 사용하는 경우 고려할 점들이 있다. 일단 응답시간(latency)이 늘어나는지 주의해야한다. 병렬 프로그래밍을 최대한 활용하여 사용자나 상품의 벡터나 인공신경망 출력값을 찾아 내적을 계산하는 것이 좋다. 인공 신경망 모델이라면 실시간 추론 대신 일괄 추론을 고려할 수도 있다. 또한 학습데이터를 준비할 때 피처 로깅방식으로 접근할 것인지 피처 재계산 방식으로 접근할 것인지 고려해야한다. 모델 기반 피처를 재계산 방식으로 학습데이터를 생성하기 위해서는 재계산이 가능한 방식으로 구현이 되어 있는지, 과거 시점의 모델들을 안전하게 접근할 수 있는지 등을 점검할 필요가 있다.