인공 신경망
인공 신경망(neural networks)의 이론, 소프트웨어, 하드웨어가 최근 비약적인 발전을 이루면서 이미지와 자연언어 처리등 여러 분야에서 큰 성과를 내고 있다. 추천 시스템에서도 인공 신경망을 바탕으로 한 방법들이 많이 도입되었다.
두개의 탑 모델
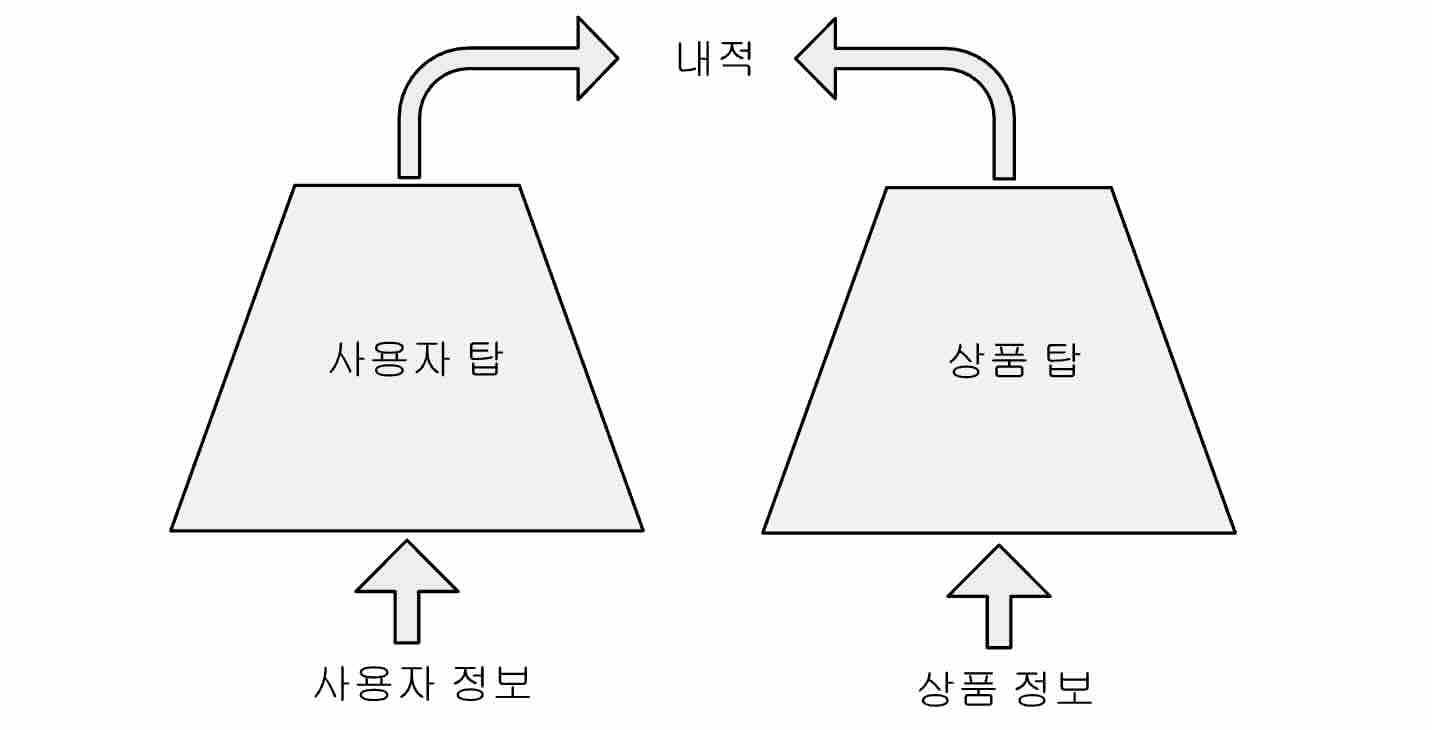
추천 시스템에 사용되는 인공 신경망 모델 중 흔히 쓰이는 방법의 하나로 두개의 탑(two-tower) 모델이 있다. 두개의 탑 모델의 신경망은 사용자 탑과 상품 탑의 두 부분으로 나누어지는데, 사용자 탑은 사용자 정보를 입력으로 받아 출력으로 사용자 벡터를 만들어 내고, 상품 탑은 상품 정보를 입력으로 받아 출력으로 상품 벡터를 만들어 내며, 사용자 탑의 출력과 상품탑의 출력사이의 내적값을 실제 기록과 비교하는 손실함수(loss function)을 이용해 학습한다. 사용자 탑, 상품 탑 등 신경망의 일부를 탑(tower)이라고 부르는 것은 인공 신경망 분야에서 흔히 쓰이는 용어이다. 사용자 탑의 출력과 상품 탑의 출력을 단위 벡터가 되도록 정규화(normalization)하는 경우도 있으며, 이 경우 두 탑의 출력 사이의 내적은 코사인과 같아진다.
행렬분해를 간단한 형태의 두개의 탑 모델로 간주할 수 있는데,
- 사용자 탑은 사용자 ID의 임베딩(embedding)만으로 구성
- 상품 탑은 상품 ID의 임베딩(embedding)만으로 구성
- 사용자 탑의 출력과 상품탑의 출력사이의 내적값을 행렬 항목과 비교하여 학습
- 손실함수로 두 값의 차이의 제곱합(sum of squares)을 사용
하면 된다. 이 같은 표현을 사용하면 파이토치(PyTorch)나 텐서플로우(Tensorflow)같은 인공 신경망 소프트웨어를 사용하여 행렬분해의 학습을 구현할 수 있다.
임베딩(embedding)이란 인공신경망에서 범주형(categorical) 정보를 다루는 대표적인 방법으로, 범주형 정보의 값 각각에 대해 정해진 길이()의 벡터변수를 지정하는 것이다. 앞선 글에서의 행렬분해와 연결시키면 이해하는데 도움이 된다. 상품 ID는 상품의 고유기호를 나타내는 범주형 정보로 허용되는 값의 경우의 수(cardinality)는 판매가 가능한 상품의 갯수와 같다. 상품 ID의 임베딩을 표현하기 위해 행렬이 필요한데 이 행렬의 가로줄의 수는 상품 ID의 경우의 수(cardinality)이고 세로줄의 수는 임베딩의 출력을 나타내는 매개변수()이다. 예를 들어 좋은서점닷컴에서 판매가 가능한 서적의 갯수가 이고, 임베딩의 매개변수 를 으로 선택했다면, 상품 ID의 임베딩을 위해 크기의 행렬이 필요하며 이를 임베딩 행렬(embedding matrix)라고 부른다. 학습 데이터에 사용자 ID의 값으로 1이 입력되면 임베딩 행렬의 첫번째 가로줄로, 사용자 ID의 값으로 2가 입력되면 임베딩 행렬의 두번째 가로줄로, ..., 사용자 ID의 값으로 이 입력되면 임베딩 행렬의 마지막 가로줄로 바꾸어 주게 되고, 이 작업을 임베딩 룩업(embedding lookup)이라고 한다. 상품 ID의 임베딩은 행렬분해에서의 상품 벡터, 사용자 ID의 임베딩은 행렬분해에서의 사용자 벡터가 된다.
두개의 탑 모델은 행렬분해에 비해 다채롭고 복잡한 표현을 가능하게 한다. 예를 들어 사용자 또는 상품의 속성정보를 활용하는 것을 들 수 있다. 좋은서점닷컴의 경우에 대해 살펴보면, 행렬분해에서는 사용자 ID와 서적 ID만을 입력으로 사용한 것에 반해, 두개의 탑 모델에서는 서적의 저자, 출판년도, 출판사, 페이지수, 분류기호등의 속성정보를 입력으로 사용할 수 있고, 사용자의 가입년도, 최근 구매 기록, 최근 장바구니 담기 기록, 배송지 정보 등을 입력으로 사용할 수 있다. 인공 신경망을 이용하면 이처럼 다양한 정보를 입력으로 사용하고 또 입력 정보 사이의 비선형적(non-linear) 의존성을 손쉽게 표현할 수 있어서 편리하다.
두개의 탑 모델의 활용
두개의 탑 모델을 이용하여 추천상품을 선정하는 과정은 행렬분해에서와 유사하고, 다른 점이라면 사용자 벡터와 상품 벡터를 인공 신경망의 추론(inference)을 통해 얻게 된다는 점이다. 즉,
- 해당 사용자 정보를 사용자 탑의 입력으로 사용하여 사용자 탑의 출력을 추론하고,
- 판매 가능한 각각의 상품들에 대해 상품 정보를 상품 탑의 입력으로 사용하여 그 출력들을 추론한 후,
- 사용자 탑과 상품 탑의 출력들 사이의 내적값을 계산
한다. 내적값이 높은 상품순으로 추천 상품을 선정한다.
두개의 탑 모델의 특징은 사용자 정보와 상품 정보를 각각의 탑 안에서 처리한 후 마지막에 내적을 통해서만 연결한다는 점이다. 바꾸어 말하면, 사용자에 대한 정보와 상품에 대한 정보사이에 비선형적(non-linear)인 관계를 표현하지 않는다. 이 같은 특징은 두개의 탑 모델을 추천시스템에서 사용하기에 좋은 장점이 된다.
장점중 하나로 사용자 탑의 추론과 상품 탑이 독립적이기 때문에 따로따로 추론할 수 있으며 추론 결과를 재사용하기도 쉽다. 추천상품 선정을 위한 계산을 따라가보며 생각해 보자. 사용자1이 좋은서점닷컴을 방문하면 추천상품 선정을 위해 사용자1의 사용자 탑 출력을 추론하고, 판매 가능한 각각의 상품들에 대해 상품 탑 출력들을 추론한 후, 출력사이의 내적값에 따라 추천 상품을 선정할 것이다. 이어서 사용자2가 좋은서점닷컴을 방문한다고 해 보자. 사용자2의 사용자 탑 출력은 사용자1의 경우와 다르지만, 가능한 각각의 상품에 대한 상품 탑 출력은 앞서 사용한 결과와 차이가 없으므로 다시 추론하지 않아도 된다. 즉, 상품 탑의 출력들은 한번 계산하고 나면 그 결과를 저장해 둔 후 재사용이 가능하다. 이는 사용자 탑과 상품 탑의 신경망이 분리되어 있기 때문에 가능하며, 그렇지 않은 경우 매 사용자 방문시 마다 전체 신경망을 추론해야 한다.
다른 장점으로 사용자 탑과 상품 탑의 출력을 행렬분해에서의 사용자 벡터와 상품 벡터처럼 사용할 수 있다. 즉, 상품 탑의 출력들을 상품 벡터처럼 사용하여 유사상품 추천에 활용할 수 있고, 상품 벡터들과 사용자 벡터들에 군집화(clustering) �알고리즘을 활용하여 상품묶음이나 사용자집단을 알아내는 분석작업에 활용이 가능하다.
자연언어처리 방법론들
두개의 탑 모델에서 사용자 탑과 상품 탑 안에서 쓸 수 있는 다양한 인공 신경망 기법이 연구되었다. 물론 경우에 따라서는 두개의 탑 구조가 아닌 경우에도 적용이 가능하다. 예를 들기 위해 다음과 같은 구매기록을 생각해 보자.
| 사용자 | 상품 | 구매시각 |
|---|---|---|
| 사용자1 | 서적1 | 2021년 10월 |
| 사용자1 | 서적3 | 2022년 7월 |
| 사용자1 | 서적7 | 2022년 10월 |
| 사용자2 | 서적2 | 2022년 1월 |
| 사용자2 | 서적4 | 2022년 5월 |
| 사용자2 | 서적6 | 2022년 4월 |
| 사용자2 | 서적8 | 2022년 11월 |
| 사용자3 | 서적3 | 2021년 9월 |
| 사용자3 | 서적7 | 2021년 12월 |
| 사용자3 | 서적9 | 2022년 3월 |
| 사용자3 | 서적10 | 2022년 4월 |
| 사용자4 | 서적2 | 2022년 8월 |
| 사용자4 | 서적5 | 2022년 10월 |
| 사용자4 | 서적6 | 2022년 12월 |
이 구매기록에서 각 사용자의 구매서적을 먼저 구매한 순으로 나열하면 다음과 같이 표현할 수 있다
| 사용자 | 구매한 상품들 |
|---|---|
| 사용자1 | 서적1 서적3 서적7 |
| 사용자2 | 서적2 서적4 서적6 서적8 |
| 사용자3 | 서적3 서적7 서적9 서적10 |
| 사용자4 | 서적2 서적5 서적6 |
여기서 서적 ID를 자연언어에서의 단어(word)로, 사용자의 구매상품 목록을 문장(sentence)으로 생각하여 자연언어처리의 방법론과 관련지을 수 있다. 추천시스템의 핵심 관심사는 "이 사용자가 다음에 구매할 상품은 무엇일까?"인데, 이를 자연언어처리의 문제로 표현해 보면 "이 문장에서 다음에 나타날 단어는 무엇일까?"가 된다. 바로 자연언어처리의 핵심 질문 가운데 하나인 "다음 단어 예측"문제이다. 다음 단어 예측을 위한 다양한 방법들을 추천 시스템에 활용할 수 있다.
- 서적1 서적3 서적7 ?
- 서적2 서적4 서적6 서적8 ?
- 서적3 서적7 서적9 서적10 ?
- 서적2 서�적5 서적6 ?
행렬분해에서는 각 사용자가 구매한 서적의 구매시각과 구매순서는 이용하지 않았던 반면, 자연언어처리 모델들에서는 사용자가 구매한 서적의 구매순서 정보를 자연스럽게 이용하여 추천결과에 반영할 수 있다. 워드임베딩(Word2Vec), 순환 신경망(Recurrent neural networks), LSTM(Long-short term memory)모델, 트랜스포머(Transformer) 등은 매우 흥미로운 주제들로, 자연언어처리분야에서와 마찬가지로 추천 시스템 분야에서도 강력한 결과를 보인다.
실시간 추론과 일괄 추론
인공 신경망을 추천 시스템에 도입할 때 실시간 추론 또는 일괄 추론을 통해 통합한다.
실시간 추론(real-time inference)이란 사용자가 좋은서점닷컴을 방문한 그 시점에 인공 신경망을 추론하는 것을 말한다. 실시간 추론으로 추천 상품을 선정하는 과정을 생각해 보면 다음과 같다.
- 사용자가 방문하면 로그인 과정을 �통해 사용자 ID를 알게 된다.
- 사용자탑의 입력으로 쓰기 위해 해당 사용자의 최근 구매 기록, 최근 장바구니 담기 기록, 배송지 정보등을 알아내야 한다. 보통 해당 정보를 저장하는 트랜잭션 데이터베이스에 질의문(query)을 실행하여 알아낸다.
- 사용자 탑을 추론한다. 추론을 위한 계산은 백엔드에서 구현하기도 하고, 별로의 서비스로 떼어내기도 한다.
- 판매가 가능한 각 서적에 대해 마찬가지 작업을 거친다. 즉, 서적의 속성정보를 트랜잭션 데이터베이스에 질의문(query)을 실행하여 알아내고, 상품 탑을 추론한다.
- 사용자 탑과 상품 탑의 출력들 사이에 내적값을 계산하고 내림순으로 정렬한다.
일괄 추론(batch inference)은 사용자가 좋은서점닷컴을 방문하기 이전에 주기적으로 인공 신경망 추론을 해두는 것을 말한다. 일괄 추론을 바탕으로 추천 상품을 선정하는데 두가지 종류의 작업들이 필요하다. 일단 사용자가 방문하기 전에 다음과 같은 작업들이 필요하다.
- 사용자 탑 추론에 필요한 정보들을 모든 사용자에 대해 한꺼번에 모은다. 보통 데이터 웨어하우스(Data Warehouse)에 질의문(query)을 실행하여 알아낸다.
- 각 사용자의 정보를 이용하여 사용자 탑을 추론한 후 그 출력을 사용자 ID를 이용하여 저장한다.
- 상품 탑 추론에 필요한 정보들을 모든 상품에 대해 한꺼번에 모은다. 보통 데이터 웨어하우스(Data Warehouse)에 질의문(query)을 실행하여 알아낸다.
- 각 상품의 정보를 이용하여 상품 탑을 추론한 후 그 출력을 상품 ID를 이용하여 저장해 둔다.
- 사용자 탑과 상품 탑의 출력들을 백엔드에서 접근이 가능하도록 옮겨둔다.
그리고 사�용자가 방문하는 시점에 다음과 같은 과정을 거친다.
- 사용자가 방문하면 로그인 과정을 통해 사용자 ID를 알게 된다.
- 사용자 ID를 이용하여 미리 계산해 둔 사용자 탑 출력을 알아낸다.
- 미리 계산해 둔 모든 상품들의 상품 탑 출력을 알아낸다.
- 사용자 탑과 상품 탑의 출력들 사이에 내적값을 계산하고 내림순으로 정렬한다.
실시간 추론의 장점은 사용자나 상품의 가장 최신정보를 사용하여 사용자 탑과 상품 탑의 출력을 추론할 수 있고, 사용자가 방문하지 않으면 사용자 탑의 추론을 하지 않아도 된다는 점이다. 그러나 단점도 만만치 않다. 일단 추론에 시간이 걸리기 때문에 응답시간(latency)이 길어지고, 파이토치(PyTorch)나 텐서플로우(Tensorflow)의 추론부분을 백엔드에 통합하거나 별도의 서비스로 운용해야 하는 부담이 있다. 사용자 탑과 상품 탑의 입력으로 쓰기 위한 정보들을 트랜잭션 데이터베이스에 질의해야 하는데 이게 트랜잭션 데이터베이스에 부담을 주거나 또는 응답시간 너무 긴 경우 별도의 캐싱(caching)을 고려해야 할 수도 있다.
일괄 추론의 장점은 미리 추론해 둔 결과를 이용하기 때문에 응답시간(latency)이 짧고, 파이토치(PyTorch)나 텐서플로우(Tensorflow)의 추론부분을 통합할 필요가 없어서 운용부담이 적다는 점이다. 반면 일괄추론을 하고 나서 다음번 추론작업을 하기 전에는 사용자나 상품의 새로운 정보가 추천상품 선정에 사용되지 않는다는 단점이 있다. 또한, 추론작업을 해 두어도 사용자가 방문하지 않으면 쓸모없는 계산이 되기도 한다.
실시간 추론을 할지 일괄 추론을 할 지를 선택할 때 기존 시스템의 응답시간(latency)에 여유가 있는지 여부와 각 방법에 필요한 기술 요소에 대한 운용 부담 등을 고려한다. 각 팀이 처한 상황에 따라 다르지만, 초기에는 일괄 추론방법의 시스템의 복잡도가 낮아 적용하기 편리한 경우가 많다. 나중에 실시간 추론으로 변경하거나 두 방법을 한꺼번에 사용하기도 한다. 기억할 점은 두개의 탑 모델처럼 사용자와 상품에 대한 신경망이 분리되어 있는 경우에 일괄 추론이 가능하다는 점이다.
데이터의 종류와 다중 작업 학습
인공 신경망 방법에서도 학습에 사용할 데이터를 결정하는 것은 매우 중요하다. 구매정보, 장바구니정보, 클릭정보등을 생각할 수 있다.
여러가지 정보를 모두 사용하되 기존의 학습방법을 바꾸지 않으면서 단순히 학습데이터를 늘리는 경우는 비교적 간단하다. 이벤트의 종류에 따라 학습 데이터에 가중치를 주어서 예를 들어 구매의 가중치는 , 장바구니 담기의 가중치는 , 클릭의 가중치는 로 하고 을 고르면 클릭에 비해 장바구니 담기의 관심도가 높고, 장바구니 담기에 비해 구매의 관심도가 높은 정도를 표현할 수 있다. 구매 기록만 사용하는 경우에는 학습 데이터의 양이 비교적 작지만, 장바구니 담기나 클릭을 포함하면 학습 데이터가 점점 많아질 것이다.
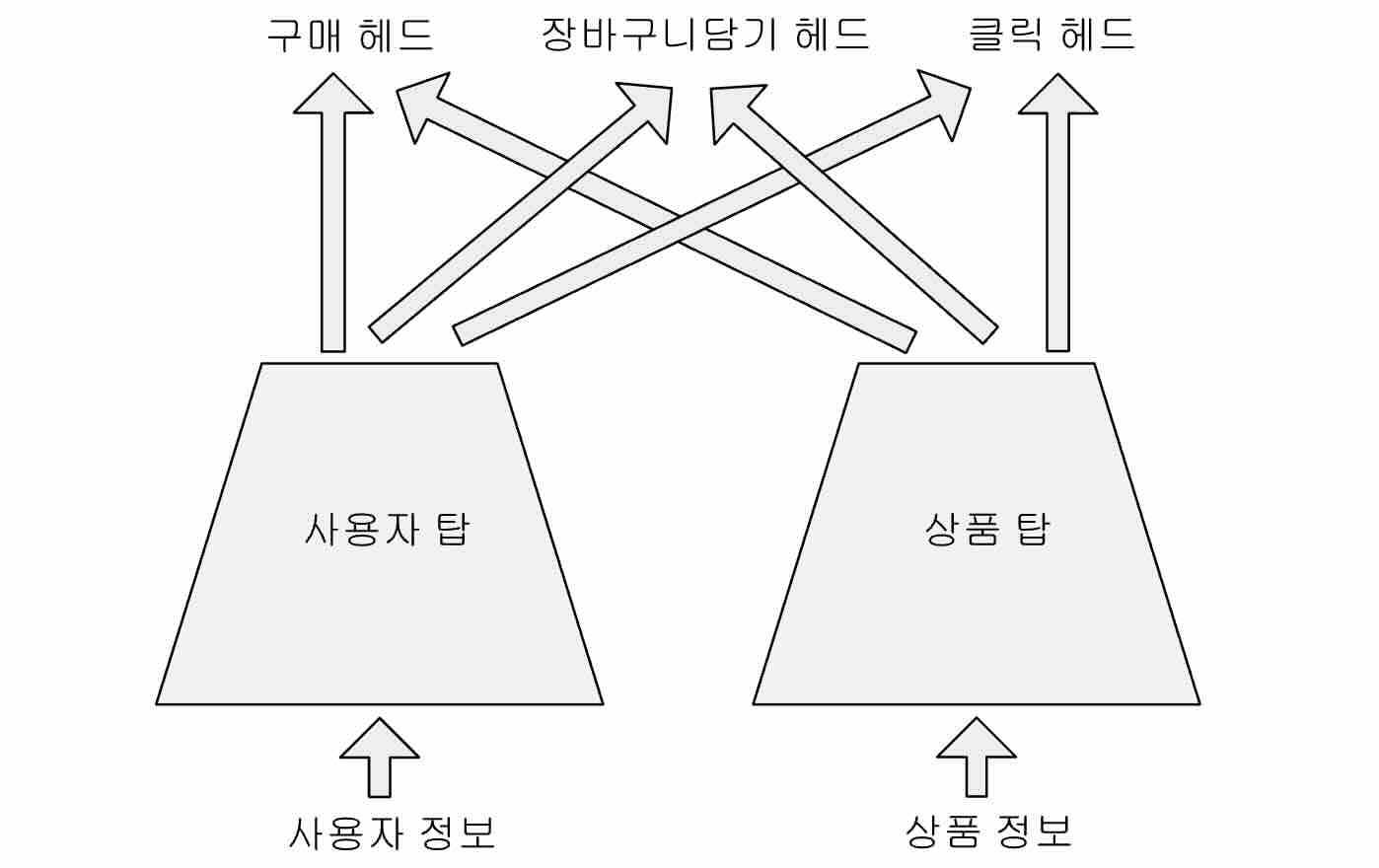
여러가지 정보를 동시에 사용하는 고도화된 방법으로 다중 작업 학습(multi-task learning)을 생각하기도 한다. 다중 작업 학습이란 기계학습(machine learning)의 방법론 가운데 하나로 �서로 다른 예측 문제를 동시에 학습함으로써, 각 예측 문제를 따로따로 학습할 때 보다 향상된 결과를 얻는 것을 목표로 한다. 추천 시스템의 경우에 적용하여 생각해 보면 구매정보를 이용하는 학습 문제, 장바구니 담기 정보를 이용하는 학습 문제, 클릭 정보를 이용하는 학습 문제를 합쳐서 동시에 학습한다. 이 때 필요한 사용자 탑과 상품 탑은 세 학습 문제에 공통적으로 적용하되, 그 공통 부분으로부터 각 학습 문제에 특화된 예측을 만드는 부분도 있다. 즉, 구매, 장바구니 담기, 클릭 등의 사용자 행동의 유사한 부분을 최대한 활용하면서도, 차이점이 존재할 때 그 차이첨들을 반영할 수 있도록 한다. 인공 신경망에서의 다중 작업 학습을 다중 헤드(multi-head) 학습이라고도 부른다.